Kubernetes에서 NestJS 그레이스풀 셧다운 제대로 하기: SIGTERM, preStop, Readiness 전환, 종료 유예시간
대상: NestJS(Express/Fastify) 서비스를 Kubernetes로 운영 중이며, 롤링 업데이트/스케일 다운 시 502/연결 끊김/처리 중 요청 유실을 줄이고 싶은 분
요약(TL;DR)
- Kubernetes는 컨테이너 종료 전에
SIGTERM을 보내고(기본), 일정 시간(terminationGracePeriodSeconds) 내 정상 종료를 기대합니다. - NestJS는
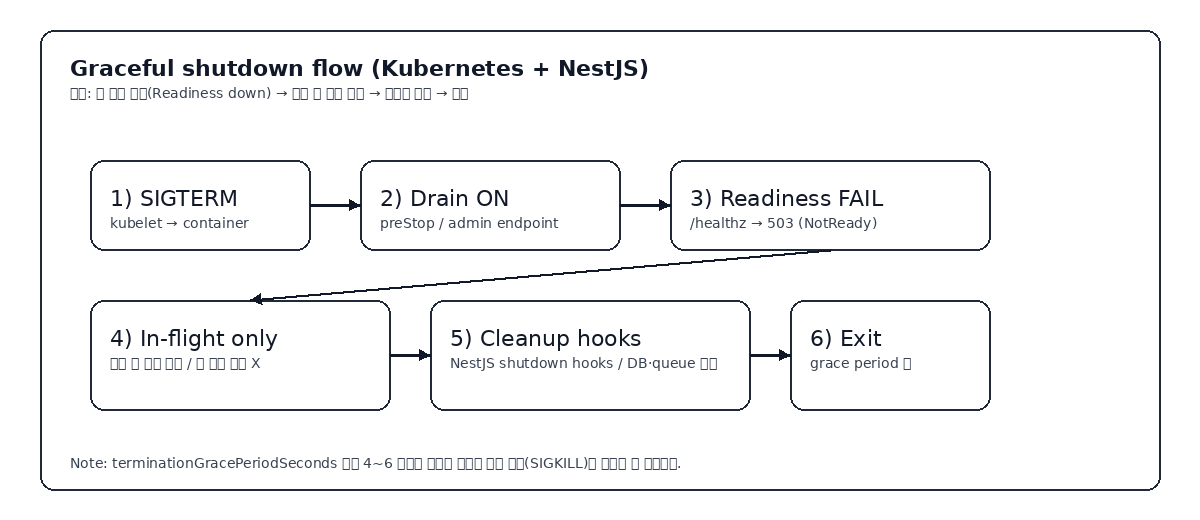
app.enableShutdownHooks()로 종료 시그널을 훅으로 받아서 서버/리소스를 정리할 수 있습니다. - 안전한 종료는 “새 요청 차단(Readiness down) → 진행 중 요청 처리 → 커넥션/리소스 정리 → 프로세스 종료” 순서가 핵심입니다.
1) 왜 롤링 업데이트 때 502/연결 끊김이 발생하나
Pod가 종료되는 순간에도 Ingress/Service/LB는 잠깐 동안 해당 Pod로 트래픽을 보낼 수 있습니다. 이때 애플리케이션이 즉시 종료되거나(프로세스 강제 종료), 서버가 먼저 닫히면서 처리 중 요청이 끊기면 사용자는 502/499(클라이언트 취소) 같은 형태로 체감합니다.
따라서 종료는 단순히 “SIGTERM 받으면 process.exit()”가 아니라, Kubernetes가 기대하는 종료 흐름에 맞춰 단계적으로 진행해야 합니다.
2) Kubernetes의 종료 시퀀스 핵심(운영자가 통제 가능한 지점)
Kubernetes 문서 기준으로, Pod가 종료될 때 kubelet은 컨테이너 런타임을 통해 프로세스에 종료 시그널을 전달하고, 유예시간 내 종료되지 않으면 강제 종료를 수행합니다. 또한 종료 과정에서 preStop 훅을 사용할 수 있습니다.
2-1. terminationGracePeriodSeconds
terminationGracePeriodSeconds는 정상 종료를 기다리는 최대 시간입니다. 이 시간보다 요청 처리/리소스 정리에 더 오래 걸리면 결국 강제 종료로 이어질 수 있으므로, 서비스 특성에 맞게 충분히 잡아야 합니다(예: 긴 폴링/대용량 처리 API).
2-2. preStop 훅(선제적으로 Readiness를 내리는 용도)
preStop는 컨테이너 종료 직전에 실행되는 훅입니다. 여기서 애플리케이션에 “지금부터 새 요청을 받지 말라”는 신호를 주거나, 잠깐 대기해 Service 엔드포인트에서 제외될 시간을 벌 수 있습니다. 단, preStop가 오래 걸리면 그만큼 유예시간을 소모합니다.
3) NestJS에서 종료 신호를 안전하게 처리하는 기본 구조
NestJS는 app.enableShutdownHooks()를 통해 종료 시그널(SIGNTERM 등)을 받아 OnModuleDestroy, BeforeApplicationShutdown, OnApplicationShutdown 같은 라이프사이클 훅을 실행할 수 있습니다(공식 문서 기준).
3-1. main.ts 예시(핵심만)
import { NestFactory } from '@nestjs/core';
import { AppModule } from './app.module';
async function bootstrap() {
const app = await NestFactory.create(AppModule);
// 종료 시그널을 Nest 라이프사이클 훅으로 전달
app.enableShutdownHooks();
await app.listen(process.env.PORT ?? 3000);
}
bootstrap();이 한 줄이 없으면, Kubernetes가 SIGTERM을 보내도 NestJS 레이어에서 정리 로직이 기대대로 호출되지 않을 수 있습니다.
3-2. “새 요청 차단(Readiness down)”은 앱 레벨에서 별도로 설계해야 한다
NestJS 자체가 자동으로 Readiness를 내리는 것은 아닙니다. 일반적으로는 아래 중 하나를 선택합니다.
- 헬스 엔드포인트(예: /healthz)의 응답을 종료 시점부터 실패로 전환하여 Readiness Probe가 Pod를 NotReady로 만들게 함
- Ingress/LB 레벨에서 드레이닝(환경에 따라 가능/불가능)
운영 관점에서는 “SIGTERM 수신 → Readiness 실패 전환 → 일정 시간 동안 진행 중 요청만 처리 → 종료” 패턴이 가장 예측 가능하고 재현이 쉽습니다.
4) Kubernetes 매니페스트 예시: Readiness + preStop + 충분한 유예시간
아래는 개념을 보여주는 예시입니다. 실제 값(유예시간, 대기시간, probe 주기)은 서비스 트래픽/요청 처리시간/인프라에 맞게 조정하세요.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nestjs-api
spec:
replicas: 2
selector:
matchLabels:
app: nestjs-api
template:
metadata:
labels:
app: nestjs-api
spec:
terminationGracePeriodSeconds: 60
containers:
- name: app
image: example.com/nestjs-api:1.0.0
ports:
- containerPort: 3000
readinessProbe:
httpGet:
path: /healthz
port: 3000
periodSeconds: 5
failureThreshold: 1
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "wget -qO- http://127.0.0.1:3000/admin/drain || true; sleep 10"]해석
/admin/drain같은 내부 엔드포인트로 “드레인 모드”를 켠 다음, 잠깐 대기하여 엔드포인트에서 제외되는 시간을 벌었습니다.- Readiness Probe는
/healthz가 실패하면 즉시(NotReady) 트래픽에서 빠지도록 잡았습니다. terminationGracePeriodSeconds는 전체 종료(훅 실행 + 대기 + 잔여 처리)에 필요한 시간을 커버해야 합니다.
5) 드레인(Drain) 모드 예시: readiness를 실패로 전환
가장 단순한 방식은 애플리케이션 내부에 “드레인 플래그”를 두고, 드레인 상태에서는 헬스 체크를 실패로 응답하는 것입니다.
// drain.service.ts (예시)
import { Injectable } from '@nestjs/common';
@Injectable()
export class DrainService {
private draining = false;
enable() {
this.draining = true;
}
isDraining() {
return this.draining;
}
}// health.controller.ts (예시)
import { Controller, Get, ServiceUnavailableException } from '@nestjs/common';
import { DrainService } from './drain.service';
@Controller()
export class HealthController {
constructor(private readonly drain: DrainService) {}
@Get('/healthz')
healthz() {
if (this.drain.isDraining()) {
// readiness를 떨어뜨리기 위해 503을 반환
throw new ServiceUnavailableException('draining');
}
return { ok: true };
}
}// admin.controller.ts (예시)
import { Controller, Post } from '@nestjs/common';
import { DrainService } from './drain.service';
@Controller('/admin')
export class AdminController {
constructor(private readonly drain: DrainService) {}
@Post('/drain')
drainOn() {
this.drain.enable();
return { draining: true };
}
}주의: 이 엔드포인트는 외부에 노출하면 위험합니다. 네트워크 정책/인증(예: mTLS, 내부망 제한)으로 반드시 보호하세요.
6) 운영 체크리스트(필수 확인 항목)
- NestJS:
app.enableShutdownHooks()적용 여부 - Readiness: 종료 시점에 즉시 실패로 전환되는 메커니즘 보유(드레인 플래그 등)
- preStop: 드레인 신호 + 짧은 대기(엔드포인트 제외 시간 확보)
- terminationGracePeriodSeconds: 최악의 요청 처리 시간을 커버
- 관측성: 종료 이벤트 로그(드레인 시작/완료, 처리 중 요청 수) 남김
- 재현 테스트: 스테이징에서
kubectl rollout restart또는 Pod 삭제로 502/요청 유실 여부 확인
7) 흔한 장애 패턴 4가지와 빠른 진단
- Readiness가 내려가지 않음: 헬스 엔드포인트가 종료 중에도 계속 200을 반환하면, 종료 Pod로 새 요청이 계속 유입될 수 있습니다.
- preStop에서 너무 오래 대기: 유예시간을 다 써서 강제 종료될 수 있습니다.
- 유예시간이 너무 짧음: 긴 요청이 끝나기 전에 프로세스가 종료됩니다.
- 종료 훅에서 블로킹 작업: DB 정리/외부 호출을 동기적으로 오래 붙잡으면 전체 종료가 지연됩니다. 종료 훅은 “최소한의 정리” 중심으로 설계하는 편이 안정적입니다.
8) 도식: 요청 드레인 관점의 종료 흐름